Machine Learning
Machine Learning I : object_detector_3d
目標
Machine Learningフレームワークの一つであるchainerを利用して物体を認識し、Depth cameraと連動してその物体との距離を求める。(リンク : chainer)
動作環境
- Ubuntu 16.04
- ROS Kinetic
- Python 2.7.16
- Intel RealSense D435
設定(Setup)
-
ROS Kineticをインストール : wiki.ros.orgを参照
- RealSense D435 ROSパッケージをインストール
$ sudo apt install ros-kinetic-realsense2-camera - 依存パッケージをインストール
- pipがない場合はインストール
$ sudo apt install python-pip - chainer, chainercv
$ pip install chainer chainercv - ros_numpy
$ sudo apt install ros-kinetic-ros-numpy
- pipがない場合はインストール
- object_detector_3dをインストール
- catkin workspaceに移動
$ cd ~/catkin_ws/src - github lfs をインストール
$ curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash $ sudo apt install git-lfs - object_detector_3d ソースコードをダウンロード, modelをダウンロード(github lfsを利用)
$ git clone https://github.com/NobutakaShimada/object_detector_3d.git - コンパイル
$ cd ~/catkin_ws $ catkin_make
- catkin workspaceに移動
実行(PCによって異なるが、実行に数秒以上必要)
- realsense & object_detector_3d node
$ roslaunch object_detector_3d run.launch - rviz
$ roslaunch object_detector_3d rviz.launch
実行画面
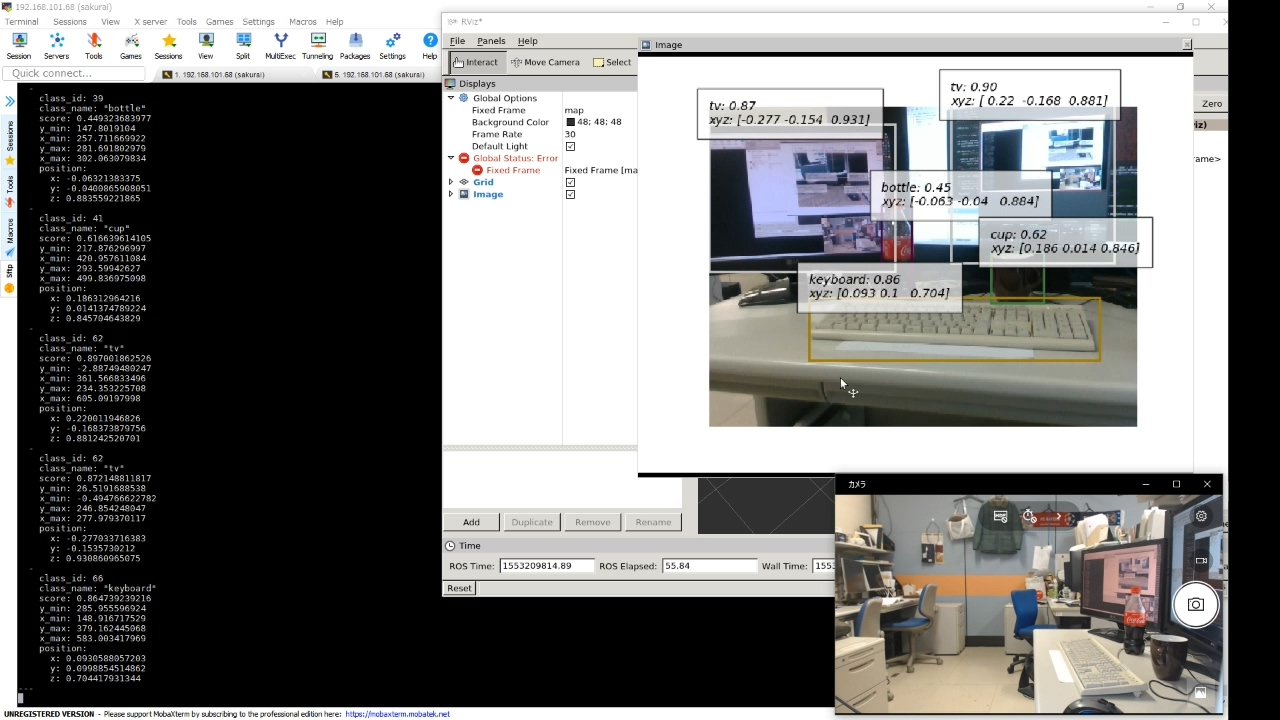
画面左:rostopic echo /object_detection_3dによる出力が表示されている。
画面右上:rvizを介して/object_detection_3d/result_imageが表示されている。
画面右上を見ると、手前からキーボード、マグカップ、瓶、2台のモニターがそれぞれ検出されていることが分かる。 それぞれの探知にキャプションが付いており、以下の情報が表示されている。
- 物体の名前
- 検出スコア。 区間[0,1]に含まれる数値で、1に近いほど信頼度が高いことを意味する。
- 物体の中心点(後述)の3次元座標。 座標系の原点はカメラの中心であり、x、y、z軸方向は、それぞれ右、下、内側方向で、単位はメートル。
5つの検出結果のうち、深さ方向の距離であるz値を見ると、物体の位置が手前から奥に行くほど値が大きくなっていることを確認できる。
ROS ノード
- Topic
- Subscribed Topics
-
/camera/color/image_raw [sensor_msgs/Image]
カラーイメージ、2Dオブジェクトの検出に利用 -
/camera/depth/color/points [sensor_msgs/PointCloud2]
3D PointCloud、3次元位置を求めるために使用
使用時、上記camera imageと時刻の同期が必要。
-
- Published Topics
- /object_detection_3d [object_detector_3d/Detection3DResult]
int32 num_detections Detection3D[] detectionsこのトピックは、検出した物体の数(num_detections)と検出情報(detections)で構成されている。 検出情報であるDetection3Dは、以下のような情報で構成されている。
int32 class_id string class_name float32 score float32 y_min float32 x_min float32 y_max float32 x_max geometry_msgs/Point position
class_id、class_nameは検出された物体の分類番号と名前で、scoreは検出の信頼度を意味する。y_min、x_min、y_max、x_maxは、検出された物体の境界ボックス(bounding box)の左上と右下の座標である。また、positionは物体の3次元位置である。
- /object_detection_3d/result_image [sensor_msgs/Image]
検出に使用された画像に検出された物体の情報が含まれた結果イメージ。上記の右のような画像となる。
- /object_detection_3d [object_detector_3d/Detection3DResult]
- その他
- sensor_msgs.CameraInfo:/camera/color/image_rawの内部パラメータ
- realsense2_camera.Extrinsics:点群の座標系からカラーカメラ座標系に変換するための外部パラメータ
- Subscribed Topics
実装の詳細 (Implementation details)
- 入出力データ
- 入力
- 2Dカメラ画像
- 3D PointCloud
- カメラの内部パラメータ
- PointCloud座標系でカメラの位置を示す外部パラメータ
- 出力
- PointCloud座標系における物体の中心点の座標
- 物体の種類
- 検出(Detection)の信頼度
- 入力
- アルゴリズムの概要
以下の手順に従って物体の3D座標を抽出- (1)カメラから得たイメージを入力として、物体検出器(Object Detector)を利用してイメージから複数の物体を検出する。
- (2)各検出に対応するbbox(bounding box)のPointCloud座標系から錐台(frustum)を求める。
- (3)各検出に対応する視錐台(view frustum)について、その中に含まれるpointのサブセットを抽出する。
- (4)各pointサブセットグループについて、中心点の座標を求める。
- (5) 2Dの検出結果と3D中心点の座標を統合し、3D検出結果を算出する。
- 各アルゴリズムの説明
- (1) 2D物体の検出(2D Object detection)
2D物体検出器は、イメージに含まれた(事前に定義された種類の)物体を検出するものを指す。 検索は、2D画像を入力すると以下のように情報が出力される。
これは、複数の物体それぞれについての予測値である。- 物体を囲むボックス(axis aligned bounding box, bbox)
- 物体の種類
- 予測の信頼度
具体的に使用する物体検出器(Object Detector)は、MS COCOデータセットによって学習されたSSD300を利用しており、この物体検出器(Object Detector)はCNNを利用して80種の物体を検出する。 具体的な検出項目は、リンク先のリストを参照のこと。 実装には、pythonのdeep learning frameworkである chainerを使用しており、特に画像処理に関しては、chainercvを使用する。
-
(2, 3) 検出した物体のpointサブセットを抽出
ここでは、前段階で得たbbox情報を利用する。個別bboxのPointCloudの全pointのうち、カメラ視点から見てbbox中に入る点のみ部分PointCloudとして抽出している。 -
(4)部分PointCloudでの中心点を計算
部分PointCloudは、対象物体と背景および遮蔽された物体から得られたpointによって構成される。これらの点を代表する一つの集約された点を求め、これを中心点とする。
中心点の定義は様々であるが、ソフトウェアは部分PointCloudの中心を中心点として定義する。
しかし、この方法は抽出した物体と物体でない部分を区別せず点データとして利用しているため、物体の形状やbboxの違いなどによって、物体そのものの中心から外れた位置が中心として算出されてしまう可能性がある。抽出した物体でない部分は部分PointCloudから除去した後、残ったPointCloudで中心を計算する方法が、より良い中心点の定義であると考えられる。 - (5) 2D検出と3D中心点の座標の統合
単純であるため省略。
- (1) 2D物体の検出(2D Object detection)
Machine Learning II: YOLO
目標
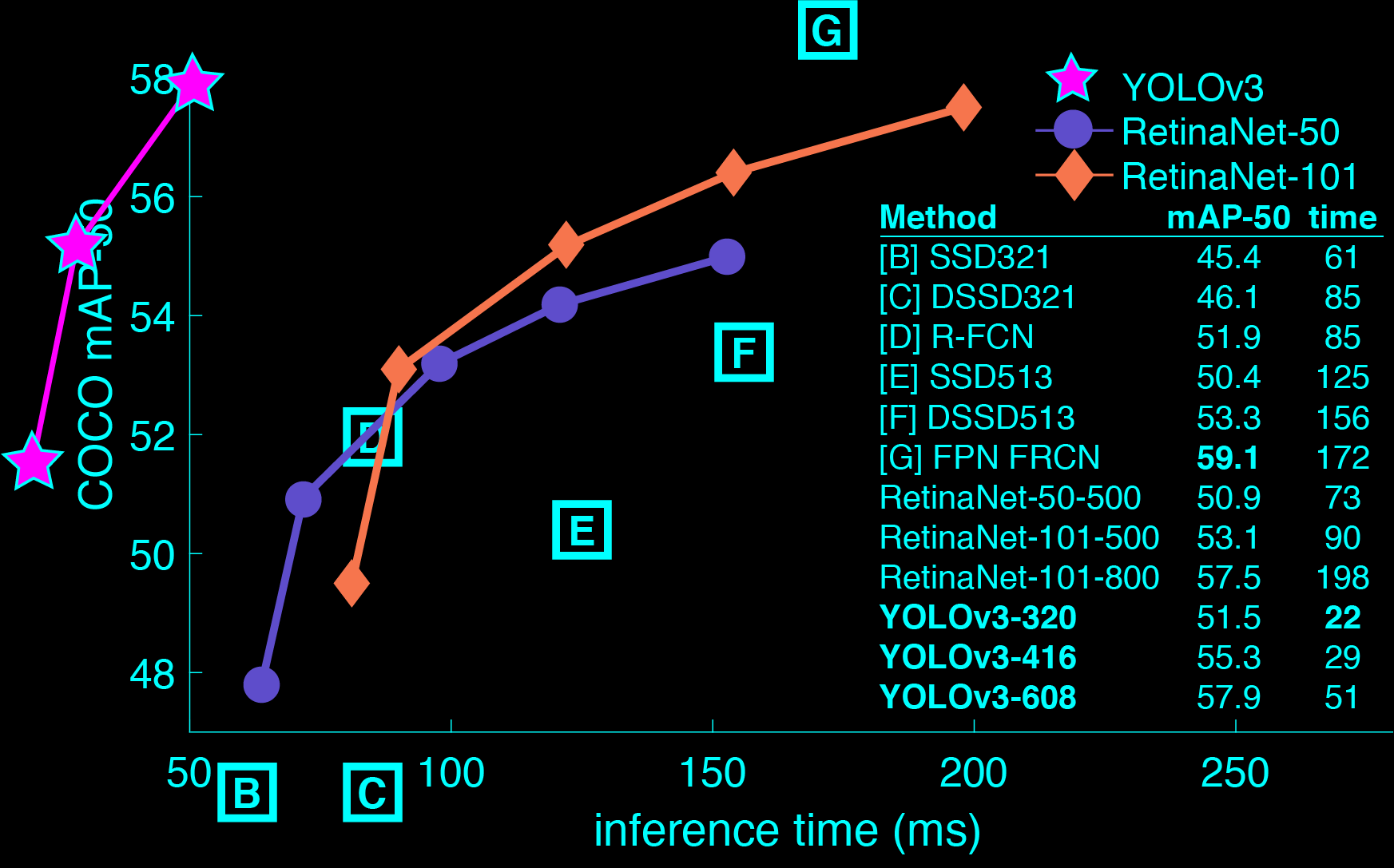
ROS環境でYOLOを使用して物体の認識を試みる。YOLO(You Only Look Once)はリアルタイム物体探索システムで、他の物体認識エンジンに比べて高速性を誇る。YOLOはDNN(deep neural network)を学習させて実行するニューラルネットワークフレームワーク(neural network framework)であるdarknetを利用して駆動。
動作環境
- Ubuntu 16.04
- ROS Kinetic
- Intel RealSense D435
設定(Setup)
-
ROS Kinetic をインストール : wiki.ros.orgを参照のこと
- RealSense D435 ROS パッケージをインストール
$ sudo apt install ros-kinetic-realsense2-camera - darknet_ros(ROS用 YOLO) インストール
- catkin workspaceに移動
$ cd ~/catkin_ws/src - ソースコードをダウンロード
$ git clone --recursive https://github.com/leggedrobotics/darknet_ros.git - コンパイル
$ cd ~/catkin_ws $ catkin_make -DCMAKE_BUILD_TYPE=Release - yolo v3用 weightをダウンロード
$ cd ~/catkin_ws/src/darknet_ros/darknet_ros/yolo_network_config/weights $ wget http://pjreddie.com/media/files/yolov3.weights - darknet_ros 設定変更
- darknet_ros/config/ros.yaml ファイルをエディタで開く。
$ nano ~/catkin_ws/src/darknet_ros/darknet_ros/config/ros.yaml - camera_readingにある topicを /camera/color/image_raw に変更して保存。
subscribers: camera_reading: topic: /camera/color/image_raw queue_size: 1
- darknet_ros/config/ros.yaml ファイルをエディタで開く。
- catkin workspaceに移動
実行(すでに学習したモデルを使用)
- realsense
$ roslaunch realsense2_camera rs_camera.launch - YOLO(darket_ros)
$ roslaunch darknet_ros darknet_ros.launch
実行画面
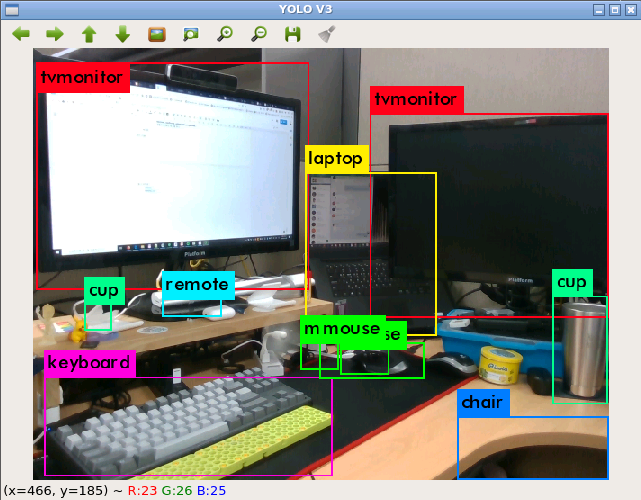
上の写真のように複数の物体が同時に認識され、認識された物体の境界にボックスが表示され、物体の名前がボックスの左上に現れる。
ROSノード
- Topic
- Subscribed Topics
- /camera/color/image_raw [sensor_msgs/Image]
カラーイメージ、物体検出に利用
- /camera/color/image_raw [sensor_msgs/Image]
- Published Topics
- /darknet_ros/bounding_boxes [darknet_ros_msgs/BoundingBoxes]
認識した物体の情報を含むtopicで、以下のようにメッセージのheader、検出に使用したイメージのheader、検出した物体の情報であるBoundingBoxで構成されている。Header header Header image_header BoundingBox[] bounding_boxes物体の情報を示すBoundingBoxは、以下の通りである。(BoundingBox.msg)
float64 probability int64 xmin int64 ymin int64 xmax int64 ymax int16 id string class検出の精度を示すprobability、検出した物体を表すイメージ上境界ボックスのx、y位置、物体の区分番号であるid、物体の種類を表すclassで構成されている。
-
/darknet_ros/detection_image [sensor_msgs/Image]
検出に使用されたイメージに、検出された物体の情報が含まれた結果イメージ - /darknet_ros/found_object [std_msgs/Int8]
検出された物体の個数を表示
- /darknet_ros/bounding_boxes [darknet_ros_msgs/BoundingBoxes]
- Subscribed Topics
- Actions
- camera_reading [sensor_msgs::Image]
イメージと結果値(検出された物体の境界ボックス)を含んだアクションを送る。
- camera_reading [sensor_msgs::Image]
-
Parameters
検出に関するパラメータの設定は、darknet_ros/config/yolo.yamlと類似した名前のファイルで行うことができる。 ROSに関するパラメータの設定は、darknet_ros/config/ros.yamlファイルで行うことができる。- image_view/enable_opencv (bool)
bounding boxを含む検出画像を示すopen cv viewerを再起動。 - image_view/wait_key_delay (int)
open cv viewerで wait key delay(ms) - yolo_model/config_file/name (string)
検出に使用するネットワークのcfg名。プログラムはdarknet_ros/yolo_network_config/cfgフォルダから、名称に合ったcfgファイルを読み込んで使用する。 - yolo_model/weight_file/name (string)
検出に使用するネットワークのweightファイル名。プログラムはdarknet_ros/yolo_network_config/weightsフォルダから名称に合ったweightsファイルを読み込んで使用する。 - yolo_model/threshold/value (float)
検出アルゴリズムのthreshold、0と1の間の値である。 - yolo_model/detection_classes/names (array of strings) ネットワークが検出可能な物体の名前(検出可能な物体のクラス)
- image_view/enable_opencv (bool)
GPUアクセラレーション
NVidia GPUがある場合、CUDAを利用するとCPUのみを使用するよりも何倍も高速な検出が可能である。CUDAをインストールすると、CMakeLists.txtファイルから自動的に認識し、コンパイル(catkin_make)時にGPUモードでコンパイルされる。